 |
1.10.0
User Documentation for MADlib
|


|
|
1.10.0
User Documentation for MADlib
|
|
This module implements the association rules data mining technique on a transactional data set. Given the names of a table and the columns, minimum support and confidence values, this function generates all single and multidimensional association rules that meet the minimum thresholds.
Association rule mining is a widely used technique for discovering relationships between variables in a large data set (e.g., items in a store that are commonly purchased together). The classic market basket analysis example using association rules is the "beer and diapers" rule. According to data mining urban legend, a study of customer purchase behavior in a supermarket found that men often purchased beer and diapers together. After making this discovery, the managers strategically placed beer and diapers closer together on the shelves and saw a dramatic increase in sales. In addition to market basket analysis, association rules are also used in bioinformatics, web analytics, and several other fields.
This type of data mining algorithm uses transactional data. Every transaction event has a unique identification, and each transaction consists of a set of items (or itemset). Purchases are considered binary (either it was purchased or not), and this implementation does not take into consideration the quantity of each item. For the MADlib association rules function, it is assumed that the data is stored in two columns with one item and transaction id per row. Transactions with multiple items will span multiple rows with one row per item.
trans_id | product
---------+---------
1 | 1
1 | 2
1 | 3
1 | 4
2 | 3
2 | 4
2 | 5
3 | 1
3 | 4
3 | 6
...
Association rules take the form "If X, then Y", where X and Y are non-empty itemsets. X and Y are called the antecedent and consequent, or the left-hand-side and right-hand-side, of the rule respectively. Using our previous example, the association rule may state "If {diapers}, then {beer}" with .2 support and .85 confidence.
The following metrics are defined for any given itemset "X".
![\[ S (X) = \frac{Total X}{Total transactions} \]](form_0.png)
Given any association rule "If X, then Y", the association rules function will also calculate the following metrics:
![\[ S (X \Rightarrow Y) = \frac{Total(X \cup Y)}{Total transactions} \]](form_1.png)
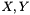 to transactions that contain
to transactions that contain 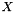 . One could view this metric as the conditional probability of
. One could view this metric as the conditional probability of 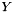 , given .
, given . 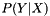
![\[ C (X \Rightarrow Y) = \frac{s(X \cap Y )}{s(X)} \]](form_6.png)
to the expected support of , assuming and are independent.
![\[ L (X \Rightarrow Y) = \frac{s(X \cap Y )}{s(X) \cdot s(Y)} \]](form_7.png)
Conviction: The ratio of expected support of occurring without assuming and 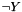 are independent, to the observed support of occuring without . If conviction is greater than 1, then this metric shows that incorrect predictions (
are independent, to the observed support of occuring without . If conviction is greater than 1, then this metric shows that incorrect predictions ( 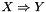 ) occur less often than if these two actions were independent. This metric can be viewed as the ratio that the association rule would be incorrect if the actions were independent (i.e. a conviction of 1.5 indicates that if the variables were independent, this rule would be incorrect 50% more often.)
) occur less often than if these two actions were independent. This metric can be viewed as the ratio that the association rule would be incorrect if the actions were independent (i.e. a conviction of 1.5 indicates that if the variables were independent, this rule would be incorrect 50% more often.)
![\[ Conv (X \Rightarrow Y) = \frac{1 - S(Y)}{1 - C(X \Rightarrow Y)} \]](form_10.png)
Although there are many algorithms that generate association rules, the classic algorithm is called Apriori [1] which we have implemented in this module. It is a breadth-first search, as opposed to depth-first searches like Eclat. Frequent itemsets of order 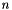 are generated from sets of order
are generated from sets of order  . Using the downward closure property, all sets must have frequent subsets. There are two steps in this algorithm; generating frequent itemsets, and using these itemsets to construct the association rules. A simplified version of the algorithm is as follows, and assumes a minimum level of support and confidence is provided:
. Using the downward closure property, all sets must have frequent subsets. There are two steps in this algorithm; generating frequent itemsets, and using these itemsets to construct the association rules. A simplified version of the algorithm is as follows, and assumes a minimum level of support and confidence is provided:
Initial step
Main algorithm
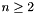 , generate itemsets of order by combining the itemsets of order . This is done by doing the union of two itemsets that have identical items except one.
, generate itemsets of order by combining the itemsets of order . This is done by doing the union of two itemsets that have identical items except one.Association rule generation
Given a frequent itemset 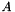 generated from the Apriori algorithm, and all subsets
generated from the Apriori algorithm, and all subsets 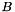 , we generate rules such that
, we generate rules such that 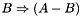 meets minimum confidence requirements.
meets minimum confidence requirements.
assoc_rules( support,
confidence,
tid_col,
item_col,
input_table,
output_schema,
verbose,
max_itemset_size
); This generates all association rules that satisfy the specified minimum support and confidence.Arguments
Minimum level of support needed for each itemset to be included in result.
Minimum level of confidence needed for each rule to be included in result.
Name of the column storing the transaction ids.
Name of the column storing the products.
Name of the table containing the input data.
The input data is expected to be of the following form:
{TABLE|VIEW} input_table (
trans_id INTEGER,
product TEXT
)The algorithm maps the product names to consecutive integer ids starting at 1. If they are already structured this way, then the ids will not change.
The name of the schema where the final results will be stored. The schema must be created before calling the function. Alternatively, use NULL to output to the current schema.
The results containing the rules, support, count, confidence, lift, and conviction are stored in the table assoc_rules in the schema specified by output_schema.
The table has the following columns.
| ruleid | integer |
|---|---|
| pre | text |
| post | text |
| count | integer |
| support | double |
| confidence | double |
| lift | double |
| conviction | double |
On Greenplum Database or Apache HAWQ, the table is distributed by the ruleid column.
The pre and post columns are the itemsets of left and right hand sides of the association rule respectively. The support, confidence, lift, and conviction columns are calculated as described earlier.
BOOLEAN, default: FALSE. Determines if details are printed for each iteration as the algorithm progresses.
Let's look at some sample transactional data and generate association rules.
DROP TABLE IF EXISTS test_data;
CREATE TABLE test_data (
trans_id INT,
product TEXT
);
INSERT INTO test_data VALUES (1, 'beer');
INSERT INTO test_data VALUES (1, 'diapers');
INSERT INTO test_data VALUES (1, 'chips');
INSERT INTO test_data VALUES (2, 'beer');
INSERT INTO test_data VALUES (2, 'diapers');
INSERT INTO test_data VALUES (3, 'beer');
INSERT INTO test_data VALUES (3, 'diapers');
INSERT INTO test_data VALUES (4, 'beer');
INSERT INTO test_data VALUES (4, 'chips');
INSERT INTO test_data VALUES (5, 'beer');
INSERT INTO test_data VALUES (6, 'beer');
INSERT INTO test_data VALUES (6, 'diapers');
INSERT INTO test_data VALUES (6, 'chips');
INSERT INTO test_data VALUES (7, 'beer');
INSERT INTO test_data VALUES (7, 'diapers');
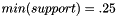 and
and 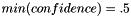 , and the output schema is set to
, and the output schema is set to NULL indicating output to the current schema. In this example we set verbose to TRUE so that we have some insight into progress of the function. We can now generate association rules as follows:
SELECT * FROM madlib.assoc_rules( .25, -- Support
.5, -- Confidence
'trans_id', -- Transaction id col
'product', -- Product col
'test_data', -- Input data
NULL, -- Output schema
TRUE -- Verbose output
);
Result (iteration details not shown): output_schema | output_table | total_rules | total_time ---------------+--------------+-------------+----------------- public | assoc_rules | 7 | 00:00:00.569254 (1 row)The association rules are stored in the assoc_rules table:
SELECT * FROM assoc_rules ORDER BY support DESC, confidence DESC;Result:
ruleid | pre | post | count | support | confidence | lift | conviction
--------+-----------------+----------------+-------+-------------------+-------------------+-------------------+-------------------
2 | {diapers} | {beer} | 5 | 0.714285714285714 | 1 | 1 | 0
6 | {beer} | {diapers} | 5 | 0.714285714285714 | 0.714285714285714 | 1 | 1
5 | {chips} | {beer} | 3 | 0.428571428571429 | 1 | 1 | 0
4 | {chips,diapers} | {beer} | 2 | 0.285714285714286 | 1 | 1 | 0
1 | {chips} | {diapers,beer} | 2 | 0.285714285714286 | 0.666666666666667 | 0.933333333333333 | 0.857142857142857
7 | {chips} | {diapers} | 2 | 0.285714285714286 | 0.666666666666667 | 0.933333333333333 | 0.857142857142857
3 | {beer,chips} | {diapers} | 2 | 0.285714285714286 | 0.666666666666667 | 0.933333333333333 | 0.857142857142857
(7 rows)
SELECT * FROM madlib.assoc_rules( .25, -- Support
.5, -- Confidence
'trans_id', -- Transaction id col
'product', -- Product col
'test_data', -- Input data
NULL, -- Output schema
TRUE, -- Verbose output
2 -- Max itemset size
);
Result (iteration details not shown): output_schema | output_table | total_rules | total_time ---------------+--------------+-------------+----------------- public | assoc_rules | 4 | 00:00:00.565176 (1 row)The association rules are again stored in the assoc_rules table:
SELECT * FROM assoc_rules ORDER BY support DESC, confidence DESC;Result:
ruleid | pre | post | count | support | confidence | lift | conviction
--------+-----------+-----------+-------+-------------------+-------------------+-------------------+-------------------
1 | {diapers} | {beer} | 5 | 0.714285714285714 | 1 | 1 | 0
2 | {beer} | {diapers} | 5 | 0.714285714285714 | 0.714285714285714 | 1 | 1
3 | {chips} | {beer} | 3 | 0.428571428571429 | 1 | 1 | 0
4 | {chips} | {diapers} | 2 | 0.285714285714286 | 0.666666666666667 | 0.933333333333333 | 0.857142857142857
(4 rows)
SELECT * FROM assoc_rules WHERE array_upper(pre,1) = 1 AND post = array['beer'];Result:
ruleid | pre | post | count | support | confidence | lift | conviction
--------+-----------+--------+-------+-------------------+------------+------+------------
1 | {diapers} | {beer} | 5 | 0.714285714285714 | 1 | 1 | 0
3 | {chips} | {beer} | 3 | 0.428571428571429 | 1 | 1 | 0
(2 rows)
The association rules function always creates a table named assoc_rules. Make a copy of this table before running the function again if you would like to keep multiple association rule tables.
[1] https://en.wikipedia.org/wiki/Apriori_algorithm
File assoc_rules.sql_in documenting the SQL function.
 1.8.13
1.8.13