 |
1.10.0
User Documentation for MADlib
|


|
|
1.10.0
User Documentation for MADlib
|
|
A conditional random field (CRF) is a type of discriminative, undirected probabilistic graphical model. A linear-chain CRF is a special type of CRF that assumes the current state depends only on the previous state.
Feature extraction modules are provided for text-analysis tasks such as part-of-speech (POS) tagging and named-entity resolution (NER). Currently, six feature types are implemented:
A Viterbi implementation is also provided to get the best label sequence and the conditional probability 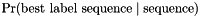 .
.
Following steps are required for CRF Learning and Inference:
train_segment_tbl and regex_tbl as input and does feature generation generating three tables dictionary_tbl, train_feature_tbl and train_featureset_tbl, that are required as an input for CRF training.
crf_train_fgen(train_segment_tbl,
regex_tbl,
label_tbl,
dictionary_tbl,
train_feature_tbl,
train_featureset_tbl)
Arguments | doc_id | INTEGER. Document id column |
|---|---|
| start_pos | INTEGER. Index of a particular term in the respective document |
| seg_text | TEXT. Term at the respective start_pos in the document |
| label | INTEGER. Label id for the term corresponding to the actual label from label_tbl |
| pattern | TEXT. Regular Expression |
|---|---|
| name | TEXT. Regular Expression name |
| id | INTEGER. Unique label id. NOTE: Must range from 0 to total number of labels in the table - 1. |
|---|---|
| label | TEXT. Label name |
| token | TEXT. Contains all the unique terms found in train_segment_tbl |
|---|---|
| total | INTEGER. Respective counts for the terms |
TEXT. Name of the training feature table to be created. The table will have the following columns:
| doc_id | INTEGER. Document id |
|---|---|
| f_size | INTEGER. Feature set size. This value will be same for all the tuples in the table |
| sparse_r | DOUBLE PRECISION[]. Array union of individual single state features (previous label, label, feature index, start position, training existance indicator), ordered by their start position. |
| dense_m | DOUBLE PRECISION[]. Array union of (previous label, label, feature index, start position, training existance indicator) of edge features ordered by start position. |
| sparse_m | DOUBLE PRECISION[]. Array union of (feature index, previous label, label) of edge features ordered by feature index. |
| f_index | INTEGER. Column containing distinct featureset ids |
|---|---|
| f_name | TEXT. Feature name |
| feature | ARRAY. Feature value. The value is of the form [L1, L2] - If L1 = -1: represents single state feature with L2 being the current label id. - If L1 != -1: represents transition feature with L1 be the previous label and L2 be the current label. |
train_feature_tbl and train_featureset_tbl tables generated in the training feature generation steps as input along with other required parameters and produces two output tables crf_stats_tbl and crf_weights_tbl.
lincrf_train(train_feature_tbl,
train_featureset_tbl,
label_tbl,
crf_stats_tbl,
crf_weights_tbl
max_iterations
)
Arguments
TEXT. Name of the feature table generated during training feature generation
TEXT. Name of the featureset table generated during training feature generation
TEXT. Name of the label table used
| coef | DOUBLE PRECISION[]. Array of coefficients |
|---|---|
| log_likelihood | DOUBLE. Log-likelihood |
| num_iterations | INTEGER. The number of iterations at which the algorithm terminated |
TEXT. Name of the table to be created creating learned feature weights. The table has the following columns:
| id | INTEGER. Feature set id |
|---|---|
| name | TEXT. Feature name |
| prev_label_id | INTEGER. Label for the previous token encountered |
| label_id | INTEGER. Label of the token with the respective feature |
| weight | DOUBLE PRECISION. Weight for the respective feature set |
crf_test_fgen(test_segment_tbl,
dictionary_tbl,
label_tbl,
regex_tbl,
crf_weights_tbl,
viterbi_mtbl,
viterbi_rtbl
)
Arguments
TEXT. Name of the testing segment table. The table is expected to have the following columns:
| doc_id | INTEGER. Document id column |
|---|---|
| start_pos | INTEGER. Index of a particular term in the respective document |
| seg_text | TEXT. Term at the respective start_pos in the document |
TEXT. Name of the dictionary table created during training feature generation (crf_train_fgen)
TEXT. Name of the label table
TEXT. Name of the regular expression table
TEXT. Name of the weights table generated during CRF training (lincrf_train)
TEXT. Name of the Viterbi M table to be created
vcrf_label(test_segment_tbl,
viterbi_mtbl,
viterbi_rtbl,
label_tbl,
result_tbl)
Arguments viterbi_mtbl generated from testing feature generation crf_test_fgen. viterbi_rtbl generated from testing feature generation crf_test_fgen. Generate text features, calculate their weights, and output the best label sequence for test data:
train_segment_tbl generating train_feature_tbl and train_featureset_tbl. SELECT madlib.crf_train_fgen(
'train_segment_tbl',
'regex_tbl',
'label_tbl',
'dictionary_tbl',
'train_feature_tbl',
'train_featureset_tbl');train_feature_tbl and train_featureset_tbl generated from previous step as an input. SELECT madlib.lincrf_train(
'train_feature_tbl',
'train_featureset_tbl',
'label_tbl',
'crf_stats_tbl',
'crf_weights_tbl',
max_iterations);test_segment_tbl generating viterbi_mtbl and viterbi_rtbl required for inferencing. SELECT madlib.crf_test_fgen(
'test_segment_tbl',
'dictionary_tbl',
'label_tbl',
'regex_tbl',
'crf_weights_tbl',
'viterbi_mtbl',
'viterbi_rtbl');. SELECT madlib.vcrf_label(
'test_segment_tbl',
'viterbi_mtbl',
'viterbi_rtbl',
'label_tbl',
'result_tbl');SELECT * FROM crf_label ORDER BY id;Result:
id | label ---+------- 0 | # 1 | $ 2 | '' ... 8 | CC 9 | CD 10 | DT 11 | EX 12 | FW 13 | IN 14 | JJ ...The regular expressions table:
SELECT * from crf_regex;
pattern | name
--------------+----------------------
^.+ing$ | endsWithIng
^[A-Z][a-z]+$ | InitCapital
^[A-Z]+$ | isAllCapital
^.*[0-9]+.*$ | containsDigit
...
The training segment table: SELECT * from train_segmenttbl ORDER BY doc_id, start_pos;
doc_id | start_pos | seg_text | label
-------+-----------+------------+-------
0 | 0 | Confidence | 18
0 | 1 | in | 13
0 | 2 | the | 10
0 | 3 | pound | 18
0 | 4 | is | 38
0 | 5 | widely | 26
...
1 | 0 | Chancellor | 19
1 | 1 | of | 13
1 | 2 | the | 10
1 | 3 | Exchequer | 19
1 | 4 | Nigel | 19
...
SELECT crf_train_fgen( 'train_segmenttbl',
'crf_regex',
'crf_label',
'crf_dictionary',
'train_featuretbl',
'train_featureset'
);
SELECT * from crf_dictionary;
Result:
token | total
----------------+-------
Hawthorne | 1
Mercedes-Benzes | 1
Wolf | 3
best-known | 1
hairline | 1
accepting | 2
purchases | 14
trash | 5
co-venture | 1
restaurants | 7
...
SELECT * from train_featuretbl;Result:
doc_id | f_size | sparse_r | dense_m | sparse_m
-------+--------+-------------------------------+---------------------------------+-----------------------
2 | 87 | {-1,13,12,0,1,-1,13,9,0,1,..} | {13,31,79,1,1,31,29,70,2,1,...} | {51,26,2,69,29,17,...}
1 | 87 | {-1,13,0,0,1,-1,13,9,0,1,...} | {13,0,62,1,1,0,13,54,2,1,13,..} | {51,26,2,69,29,17,...}
SELECT * from train_featureset;
f_index | f_name | feature
--------+---------------+---------
1 | R_endsWithED | {-1,29}
13 | W_outweigh | {-1,26}
29 | U | {-1,5}
31 | U | {-1,29}
33 | U | {-1,12}
35 | W_a | {-1,2}
37 | W_possible | {-1,6}
15 | W_signaled | {-1,29}
17 | End. | {-1,43}
49 | W_'s | {-1,16}
63 | W_acquire | {-1,26}
51 | E. | {26,2}
69 | E. | {29,17}
71 | E. | {2,11}
83 | W_the | {-1,2}
85 | E. | {16,11}
4 | W_return | {-1,11}
...
SELECT lincrf_train( 'train_featuretbl',
'train_featureset',
'crf_label',
'crf_stats_tbl',
'crf_weights_tbl',
20
);
lincrf_train
-----------------------------------------------------------------------------------
CRF Train successful. Results stored in the specified CRF stats and weights table
lincrf
View the feature weight table. SELECT * from crf_weights_tbl;Result:
id | name | prev_label_id | label_id | weight ---+---------------+---------------+----------+------------------- 1 | R_endsWithED | -1 | 29 | 1.54128249293937 13 | W_outweigh | -1 | 26 | 1.70691232223653 29 | U | -1 | 5 | 1.40708515869008 31 | U | -1 | 29 | 0.830356200936407 33 | U | -1 | 12 | 0.769587378281239 35 | W_a | -1 | 2 | 2.68470625883726 37 | W_possible | -1 | 6 | 3.41773107604468 15 | W_signaled | -1 | 29 | 1.68187039165771 17 | End. | -1 | 43 | 3.07687845517082 49 | W_'s | -1 | 16 | 2.61430312229883 63 | W_acquire | -1 | 26 | 1.67247047385797 51 | E. | 26 | 2 | 3.0114240119435 69 | E. | 29 | 17 | 2.82385531733866 71 | E. | 2 | 11 | 3.00970493772732 83 | W_the | -1 | 2 | 2.58742315259326 ...
SELECT * from test_segmenttbl ORDER BY doc_id, start_pos;Result:
doc_id | start_pos | seg_text
-------+-----------+---------------
0 | 0 | Rockwell
0 | 1 | International
0 | 2 | Corp.
0 | 3 | 's
0 | 4 | Tulsa
0 | 5 | unit
0 | 6 | said
...
1 | 0 | Rockwell
1 | 1 | said
1 | 2 | the
1 | 3 | agreement
1 | 4 | calls
...
SELECT crf_test_fgen( 'test_segmenttbl',
'crf_dictionary',
'crf_label',
'crf_regex',
'crf_weights_tbl',
'viterbi_mtbl',
'viterbi_rtbl'
);
extracted_best_labels.
SELECT vcrf_label( 'test_segmenttbl',
'viterbi_mtbl',
'viterbi_rtbl',
'crf_label',
'extracted_best_labels'
);
View the best labels. SELECT * FROM extracted_best_labels;Result:
doc_id | start_pos | seg_text | label | id | max_pos | prob
-------+-----------+---------------+-------+----+---------+----------
0 | 0 | Rockwell | NNP | 19 | 27 | 0.000269
0 | 1 | International | NNP | 19 | 27 | 0.000269
0 | 2 | Corp. | NNP | 19 | 27 | 0.000269
0 | 3 | 's | NNP | 19 | 27 | 0.000269
...
1 | 0 | Rockwell | NNP | 19 | 16 | 0.000168
1 | 1 | said | NNP | 19 | 16 | 0.000168
1 | 2 | the | DT | 10 | 16 | 0.000168
1 | 3 | agreement | JJ | 14 | 16 | 0.000168
1 | 4 | calls | NNS | 21 | 16 | 0.000168
...
Specifically, a linear-chain CRF is a distribution defined by
![\[ p_\lambda(\boldsymbol y | \boldsymbol x) = \frac{\exp{\sum_{m=1}^M \lambda_m F_m(\boldsymbol x, \boldsymbol y)}}{Z_\lambda(\boldsymbol x)} \,. \]](form_57.png)
where
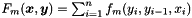 is a global feature function that is a sum along a sequence
is a global feature function that is a sum along a sequence 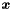 of length
of length 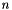
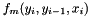 is a local feature function dependent on the current token label
is a local feature function dependent on the current token label 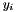 , the previous token label
, the previous token label 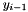 , and the observation
, and the observation 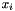
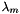 is the corresponding feature weight
is the corresponding feature weight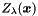 is an instance-specific normalizer
is an instance-specific normalizer
![\[ Z_\lambda(\boldsymbol x) = \sum_{\boldsymbol y'} \exp{\sum_{m=1}^M \lambda_m F_m(\boldsymbol x, \boldsymbol y')} \]](form_66.png)
A linear-chain CRF estimates the weights by maximizing the log-likelihood of a given training set 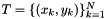 .
.
The log-likelihood is defined as
![\[ \ell_{\lambda}=\sum_k \log p_\lambda(y_k|x_k) =\sum_k[\sum_{m=1}^M \lambda_m F_m(x_k,y_k) - \log Z_\lambda(x_k)] \]](form_68.png)
and the zero of its gradient
![\[ \nabla \ell_{\lambda}=\sum_k[F(x_k,y_k)-E_{p_\lambda(Y|x_k)}[F(x_k,Y)]] \]](form_69.png)
is found since the maximum likelihood is reached when the empirical average of the global feature vector equals its model expectation. The MADlib implementation uses limited-memory BFGS (L-BFGS), a limited-memory variation of the Broyden–Fletcher–Goldfarb–Shanno (BFGS) update, a quasi-Newton method for unconstrained optimization.
![$E_{p_\lambda(Y|x)}[F(x,Y)]$](form_70.png) is found by using a variant of the forward-backward algorithm:
is found by using a variant of the forward-backward algorithm:
![\[ E_{p_\lambda(Y|x)}[F(x,Y)] = \sum_y p_\lambda(y|x)F(x,y) = \sum_i\frac{\alpha_{i-1}(f_i*M_i)\beta_i^T}{Z_\lambda(x)} \]](form_71.png)
![\[ Z_\lambda(x) = \alpha_n.1^T \]](form_72.png)
where 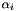 and
and 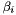 are the forward and backward state cost vectors defined by
are the forward and backward state cost vectors defined by
![\[ \alpha_i = \begin{cases} \alpha_{i-1}M_i, & 0<i<=n\\ 1, & i=0 \end{cases}\\ \]](form_75.png)
![\[ \beta_i^T = \begin{cases} M_{i+1}\beta_{i+1}^T, & 1<=i<n\\ 1, & i=n \end{cases} \]](form_76.png)
To avoid overfitting, we penalize the likelihood with a spherical Gaussian weight prior:
![\[ \ell_{\lambda}^\prime=\sum_k[\sum_{m=1}^M \lambda_m F_m(x_k,y_k) - \log Z_\lambda(x_k)] - \frac{\lVert \lambda \rVert^2}{2\sigma ^2} \]](form_77.png)
![\[ \nabla \ell_{\lambda}^\prime=\sum_k[F(x_k,y_k) - E_{p_\lambda(Y|x_k)}[F(x_k,Y)]] - \frac{\lambda}{\sigma ^2} \]](form_78.png)
[2] Wikipedia, Conditional Random Field, http://en.wikipedia.org/wiki/Conditional_random_field
[3] A. Jaiswal, S.Tawari, I. Mansuri, K. Mittal, C. Tiwari (2012), CRF, http://crf.sourceforge.net/
[4] D. Wang, ViterbiCRF, http://www.cs.berkeley.edu/~daisyw/ViterbiCRF.html
[5] Wikipedia, Viterbi Algorithm, http://en.wikipedia.org/wiki/Viterbi_algorithm
[6] J. Nocedal. Updating Quasi-Newton Matrices with Limited Storage (1980), Mathematics of Computation 35, pp. 773-782
[7] J. Nocedal, Software for Large-scale Unconstrained Optimization, http://users.eecs.northwestern.edu/~nocedal/lbfgs.html
File crf.sql_in crf_feature_gen.sql_in viterbi.sql_in (documenting the SQL functions)
 1.8.13
1.8.13