 |
1.10.0
User Documentation for MADlib
|


|
|
1.10.0
User Documentation for MADlib
|
|
Binomial logistic regression models the relationship between a dichotomous dependent variable and one or more predictor variables. The dependent variable may be a Boolean value or a categorial variable that can be represented with a Boolean expression. The probabilities describing the possible outcomes of a single trial are modeled, as a function of the predictor variables, using a logistic function.
logregr_train( source_table,
out_table,
dependent_varname,
independent_varname,
grouping_cols,
max_iter,
optimizer,
tolerance,
verbose
)
Arguments TEXT. The name of the table containing the training data.
TEXT. Name of the generated table containing the output model.
The output table produced by the logistic regression training function contains the following columns:
| <...> | Text. Grouping columns, if provided in input. This could be multiple columns depending on the |
|---|---|
| coef | FLOAT8. Vector of the coefficients of the regression. |
| log_likelihood | FLOAT8. The log-likelihood |
| std_err | FLOAT8[]. Vector of the standard error of the coefficients. |
| z_stats | FLOAT8[]. Vector of the z-statistics of the coefficients. |
| p_values | FLOAT8[]. Vector of the p-values of the coefficients. |
| odds_ratios | FLOAT8[]. The odds ratio, |
| condition_no | FLOAT8[]. The condition number of the |
| num_iterations | INTEGER. The number of iterations actually completed. This would be different from the nIterations argument if a tolerance parameter is provided and the algorithm converges before all iterations are completed. |
| num_rows_processed | INTEGER. The number of rows actually processed, which is equal to the total number of rows in the source table minus the number of skipped rows. |
| num_missing_rows_skipped | INTEGER. The number of rows skipped during the training. A row will be skipped if the independent_varname is NULL or contains NULL values. |
A summary table named <out_table>_summary is also created at the same time, which has the following columns:
| source_table | The data source table name. |
|---|---|
| out_table | The output table name. |
| dependent_varname | The dependent variable. |
| independent_varname | The independent variables |
| optimizer_params | A string that contains all the optimizer parameters, and has the form of 'optimizer=..., max_iter=..., tolerance=...' |
| num_all_groups | How many groups of data were fit by the logistic model. |
| num_failed_groups | How many groups' fitting processes failed. |
| num_rows_processed | The total number of rows usd in the computation. |
| num_missing_rows_skipped | The total number of rows skipped. |
TEXT. Name of the dependent variable column (of type BOOLEAN) in the training data or an expression evaluating to a BOOLEAN.
TEXT. Expression list to evaluate for the independent variables. An intercept variable is not assumed. It is common to provide an explicit intercept term by including a single constant 1 term in the independent variable list.
TEXT, default: NULL. An expression list used to group the input dataset into discrete groups, running one regression per group. Similar to the SQL "GROUP BY" clause. When this value is NULL, no grouping is used and a single result model is generated.
INTEGER, default: 20. The maximum number of iterations that are allowed.
TEXT, default: 'irls'. The name of the optimizer to use:
| 'newton' or 'irls' | Iteratively reweighted least squares |
|---|---|
| 'cg' | conjugate gradient |
| 'igd' | incremental gradient descent. |
FLOAT8, default: 0.0001. The difference between log-likelihood values in successive iterations that should indicate convergence. A zero disables the convergence criterion, so that execution stops after n iterations have completed.
The function to predict the boolean value (True/False) of the dependent variable has the following syntax:
logregr_predict(coefficients,
ind_var
)
The function to predict the probability of the dependent variable being True has the following syntax:
logregr_predict_prob(coefficients,
ind_var
)
Arguments
DOUBLE PRECISION[]. Model coefficients obtained from logregr_train().
CREATE TABLE patients( id INTEGER NOT NULL,
second_attack INTEGER,
treatment INTEGER,
trait_anxiety INTEGER);
COPY patients FROM STDIN WITH DELIMITER '|';
1 | 1 | 1 | 70
3 | 1 | 1 | 50
5 | 1 | 0 | 40
7 | 1 | 0 | 75
9 | 1 | 0 | 70
11 | 0 | 1 | 65
13 | 0 | 1 | 45
15 | 0 | 1 | 40
17 | 0 | 0 | 55
19 | 0 | 0 | 50
2 | 1 | 1 | 80
4 | 1 | 0 | 60
6 | 1 | 0 | 65
8 | 1 | 0 | 80
10 | 1 | 0 | 60
12 | 0 | 1 | 50
14 | 0 | 1 | 35
16 | 0 | 1 | 50
18 | 0 | 0 | 45
20 | 0 | 0 | 60
\.
SELECT madlib.logregr_train( 'patients',
'patients_logregr',
'second_attack',
'ARRAY[1, treatment, trait_anxiety]',
NULL,
20,
'irls'
);
(Note that in this example we are dynamically creating the array of independent variables from column names. If you have large numbers of independent variables beyond the PostgreSQL limit of maximum columns per table, you would pre-build the arrays and store them in a single column.)-- Set extended display on for easier reading of output \x on SELECT * from patients_logregr;Result:
coef | {5.59049410898112,2.11077546770772,-0.237276684606453}
log_likelihood | -467.214718489873
std_err | {0.318943457652178,0.101518723785383,0.294509929481773}
z_stats | {17.5281667482197,20.7919819024719,-0.805666162169712}
p_values | {8.73403463417837e-69,5.11539430631541e-96,0.420435365338518}
odds_ratios | {267.867942976278,8.2546400100702,0.788773016471171}
condition_no | 179.186118573205
num_iterations | 9
\x off
SELECT unnest(array['intercept', 'treatment', 'trait_anxiety']) as attribute,
unnest(coef) as coefficient,
unnest(std_err) as standard_error,
unnest(z_stats) as z_stat,
unnest(p_values) as pvalue,
unnest(odds_ratios) as odds_ratio
FROM patients_logregr;
\x off
-- Display prediction value along with the original value
SELECT p.id, madlib.logregr_predict(coef, ARRAY[1, treatment, trait_anxiety]),
p.second_attack
FROM patients p, patients_logregr m
ORDER BY p.id;
\x off -- Display prediction value along with the original value SELECT p.id, madlib.logregr_predict_prob(coef, ARRAY[1, treatment, trait_anxiety]) FROM patients p, patients_logregr m ORDER BY p.id;
(Binomial) logistic regression refers to a stochastic model in which the conditional mean of the dependent dichotomous variable (usually denoted 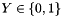 ) is the logistic function of an affine function of the vector of independent variables (usually denoted
) is the logistic function of an affine function of the vector of independent variables (usually denoted 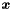 ). That is,
). That is,
![\[ E[Y \mid \boldsymbol x] = \sigma(\boldsymbol c^T \boldsymbol x) \]](form_95.png)
for some unknown vector of coefficients 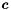 and where
and where 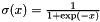 is the logistic function. Logistic regression finds the vector of coefficients that maximizes the likelihood of the observations.
is the logistic function. Logistic regression finds the vector of coefficients that maximizes the likelihood of the observations.
Let
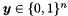 denote the vector of observed dependent variables, with
denote the vector of observed dependent variables, with 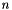 rows, containing the observed values of the dependent variable,
rows, containing the observed values of the dependent variable,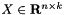 denote the design matrix with
denote the design matrix with 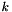 columns and rows, containing all observed vectors of independent variables
columns and rows, containing all observed vectors of independent variables 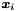 as rows.
as rows.By definition,
![\[ P[Y = y_i | \boldsymbol x_i] = \sigma((-1)^{(1 - y_i)} \cdot \boldsymbol c^T \boldsymbol x_i) \,. \]](form_356.png)
Maximizing the likelihood 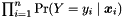 is equivalent to maximizing the log-likelihood
is equivalent to maximizing the log-likelihood 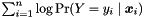 , which simplifies to
, which simplifies to
![\[ l(\boldsymbol c) = -\sum_{i=1}^n \log(1 + \exp((-1)^{(1 - y_i)} \cdot \boldsymbol c^T \boldsymbol x_i)) \,. \]](form_357.png)
The Hessian of this objective is 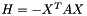 where
where 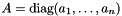 is the diagonal matrix with
is the diagonal matrix with 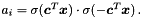 Since
Since 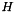 is non-positive definite,
is non-positive definite, 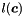 is convex. There are many techniques for solving convex optimization problems. Currently, logistic regression in MADlib can use one of three algorithms:
is convex. There are many techniques for solving convex optimization problems. Currently, logistic regression in MADlib can use one of three algorithms:
We estimate the standard error for coefficient 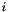 as
as
![\[ \mathit{se}(c_i) = \left( (X^T A X)^{-1} \right)_{ii} \,. \]](form_109.png)
The Wald z-statistic is
![\[ z_i = \frac{c_i}{\mathit{se}(c_i)} \,. \]](form_110.png)
The Wald 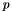 -value for coefficient gives the probability (under the assumptions inherent in the Wald test) of seeing a value at least as extreme as the one observed, provided that the null hypothesis (
-value for coefficient gives the probability (under the assumptions inherent in the Wald test) of seeing a value at least as extreme as the one observed, provided that the null hypothesis ( 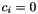 ) is true. Letting
) is true. Letting 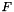 denote the cumulative density function of a standard normal distribution, the Wald -value for coefficient is therefore
denote the cumulative density function of a standard normal distribution, the Wald -value for coefficient is therefore
![\[ p_i = \Pr(|Z| \geq |z_i|) = 2 \cdot (1 - F( |z_i| )) \]](form_114.png)
where 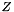 is a standard normally distributed random variable.
is a standard normally distributed random variable.
The odds ratio for coefficient is estimated as 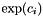 .
.
The condition number is computed as 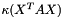 during the iteration immediately preceding convergence (i.e.,
during the iteration immediately preceding convergence (i.e., 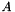 is computed using the coefficients of the previous iteration). A large condition number (say, more than 1000) indicates the presence of significant multicollinearity.
is computed using the coefficients of the previous iteration). A large condition number (say, more than 1000) indicates the presence of significant multicollinearity.
A somewhat random selection of nice write-ups, with valuable pointers into further literature.
[1] Cosma Shalizi: Statistics 36-350: Data Mining, Lecture Notes, 18 November 2009, http://www.stat.cmu.edu/~cshalizi/350/lectures/26/lecture-26.pdf
[2] Thomas P. Minka: A comparison of numerical optimizers for logistic regression, 2003 (revised Mar 26, 2007), http://research.microsoft.com/en-us/um/people/minka/papers/logreg/minka-logreg.pdf
[3] Paul Komarek, Andrew W. Moore: Making Logistic Regression A Core Data Mining Tool With TR-IRLS, IEEE International Conference on Data Mining 2005, pp. 685-688, http://komarix.org/ac/papers/tr-irls.short.pdf
[4] D. P. Bertsekas: Incremental gradient, subgradient, and proximal methods for convex optimization: a survey, Technical report, Laboratory for Information and Decision Systems, 2010, http://web.mit.edu/dimitrib/www/Incremental_Survey_LIDS.pdf
[5] A. Nemirovski, A. Juditsky, G. Lan, and A. Shapiro: Robust stochastic approximation approach to stochastic programming, SIAM Journal on Optimization, 19(4), 2009, http://www2.isye.gatech.edu/~nemirovs/SIOPT_RSA_2009.pdf
File logistic.sql_in documenting the training function
 1.8.13
1.8.13 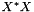 matrix. A high condition number is usually an indication that there may be some numeric instability in the result yielding a less reliable model. A high condition number often results when there is a significant amount of colinearity in the underlying design matrix, in which case other regression techniques may be more appropriate.
matrix. A high condition number is usually an indication that there may be some numeric instability in the result yielding a less reliable model. A high condition number often results when there is a significant amount of colinearity in the underlying design matrix, in which case other regression techniques may be more appropriate.