 |
1.10.0
User Documentation for MADlib
|


|
|
1.10.0
User Documentation for MADlib
|
|
Support Vector Machines (SVMs) are models for regression and classification tasks. SVM models have two particularly desirable features: robustness in the presence of noisy data and applicability to a variety of data configurations. At its core, a linear SVM model is a hyperplane separating two distinct classes of data (in the case of classification problems), in such a way that the distance between the hyperplane and the nearest training data point (called the margin) is maximized. Vectors that lie on this margin are called support vectors. With the support vectors fixed, perturbations of vectors beyond the margin will not affect the model; this contributes to the model’s robustness. By substituting a kernel function for the usual inner product, one can approximate a large variety of decision boundaries in addition to linear hyperplanes.
svm_classification(
source_table,
model_table,
dependent_varname,
independent_varname,
kernel_func,
kernel_params,
grouping_col,
params,
verbose
)
Arguments TEXT. Name of the table containing the training data.
TEXT. Name of the output table containing the model. Details of the output tables are provided below.
TEXT. Name of the dependent variable column. For classification, this column can contain values of any type, but must assume exactly two distinct values. Otherwise, an error will be thrown.
TEXT. Expression list to evaluate for the independent variables. An intercept variable should not be included as part of this expression. See 'fit_intercept' in the kernel params for info on intercepts. Please note that expression should be able to be cast to DOUBLE PRECISION[].
TEXT, default: 'linear'. Type of kernel. Currently three kernel types are supported: 'linear', 'gaussian', and 'polynomial'. The text can be any subset of the three strings; for e.g., kernel_func='ga' will create a Gaussian kernel.
TEXT, defaults: NULL. Parameters for non-linear kernel in a comma-separated string of key-value pairs. The actual parameters differ depending on the value of kernel_func. See the description below for details.
TEXT, default: NULL. An expression list used to group the input dataset into discrete groups, which results in running one model per group. Similar to the SQL "GROUP BY" clause. When this value is NULL, no grouping is used and a single model is generated. Please note that cross validation is not supported if grouping is used.
TEXT, default: NULL. Parameters for optimization and regularization in a comma-separated string of key-value pairs. If a list of values is provided, then cross-validation will be performed to select the best value from the list. See the description below for details.
Output tables
The model table produced by SVM contains the following columns:
| coef | FLOAT8. Vector of coefficients. |
|---|---|
| grouping_key | TEXT Identifies the group to which the datum belongs. |
| num_rows_processed | BIGINT. Numbers of rows processed. |
| num_rows_skipped | BIGINT. Numbers of rows skipped due to missing values or failures. |
| num_iterations | INTEGER. Number of iterations completed by stochastic gradient descent algorithm. The algorithm either converged in this number of iterations or hit the maximum number specified in the optimization parameters. |
| loss | FLOAT8. Value of the objective function of SVM. See Technical Background section below for more details. |
| norm_of_gradient | FLOAT8. Value of the L2-norm of the (sub)-gradient of the objective function. |
| __dep_var_mapping | TEXT[]. Vector of dependent variable labels. The first entry corresponds to -1 and the second to +1. For internal use only. |
An auxiliary table named <model_table>_random is created if the kernel is not linear. It contains data needed to embed test data into a random feature space (see references [2,3]). This data is used internally by svm_predict and not meaningful on its own to the user, so you can ignore it.
A summary table named <model_table>_summary is also created, which has the following columns:
| method | 'svm' |
|---|---|
| version_number | Version of MADlib which was used to generate the model. |
| source_table | The data source table name. |
| model_table | The model table name. |
| dependent_varname | The dependent variable. |
| independent_varname | The independent variables. |
| kernel_func | The kernel function. |
| kernel_parameters | The kernel parameters, as well as random feature map data. |
| grouping_col | Columns on which to group. |
| optim_params | A string containing the optimization parameters. |
| reg_params | A string containing the regularization parameters. |
| num_all_groups | Number of groups in SVM training. |
| num_failed_groups | Number of failed groups in SVM training. |
| total_rows_processed | Total numbers of rows processed in all groups. |
| total_rows_skipped | Total numbers of rows skipped in all groups due to missing values or failures. |
svm_regression(source_table,
model_table,
dependent_varname,
independent_varname,
kernel_func,
kernel_params,
grouping_col,
params,
verbose
)
Arguments
Specifications for regression are largely the same as for classification. In the model table, there is no dependent variable mapping. The following arguments have specifications which differ from svm_classification:
svm_one_class(
source_table,
model_table,
independent_varname,
kernel_func,
kernel_params,
grouping_col,
params,
verbose
)
Arguments Specifications for novelty detection are largely the same as for classification, except the dependent variable name is not specified. The model table is the same as that for classification.
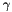 in the Radius Basis Function kernel, i.e.,
in the Radius Basis Function kernel, i.e., 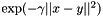 . Choosing a proper value for gamma is critical to the performance of kernel machine; e.g., while a large gamma tends to cause overfitting, a small gamma will make the model too constrained to capture the complexity of the data.
. Choosing a proper value for gamma is critical to the performance of kernel machine; e.g., while a large gamma tends to cause overfitting, a small gamma will make the model too constrained to capture the complexity of the data.  in
in  . Must be larger than or equal to 0. When it is 0, the polynomial kernel is in homogeneous form.
. Must be larger than or equal to 0. When it is 0, the polynomial kernel is in homogeneous form. 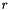 in .
in . Hyperparameter optimization can be carried out using the built-in cross validation mechanism, which is activated by assigning a value greater than 1 to the parameter n_folds in params. Please note that cross validation is not supported if grouping is used.
The values of a parameter to cross validate should be provided in a list. For example, if one wanted to regularize with the L1 norm and use a lambda value from the set {0.3, 0.4, 0.5}, one might input 'lambda={0.3, 0.4, 0.5}, norm=L1, n_folds=10' in params. Note that the use of '{}' and '[]' are both valid here.
'init_stepsize = <value>, decay_factor = <value>, max_iter = <value>, tolerance = <value>, lambda = <value>, norm = <value>, epsilon = <value>, eps_table = <value>, validation_result = <value>, n_folds = <value>, class_weight = <value>'
Parameters
Default: [0.01]. Also known as the initial learning rate. A small value is usually desirable to ensure convergence, while a large value provides more room for progress during training. Since the best value depends on the condition number of the data, in practice one often searches in an exponential grid using built-in cross validation; e.g., "init_stepsize = [1, 0.1, 0.001]". To reduce training time, it is common to run cross validation on a subsampled dataset, since this usually provides a good estimate of the condition number of the whole dataset. Then the resulting init_stepsize can be run on the whole dataset.
Default: [0.9]. Control the learning rate schedule: 0 means constant rate; <-1 means inverse scaling, i.e., stepsize = init_stepsize / iteration; > 0 means <exponential decay, i.e., stepsize = init_stepsize * decay_factor^iteration.
Default: [100]. The maximum number of iterations allowed.
Default: 1e-10. The criterion to end iterations. The training stops whenever <the difference between the training models of two consecutive iterations is <smaller than tolerance or the iteration number is larger than max_iter.
Default: [0.01]. Regularization parameter. Must be non-negative.
Default: 'L2'. Name of the regularization, either 'L2' or 'L1'.
Default: [0.01]. Determines the 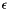 for -regression. Ignored during classification. When training the model, differences of less than between estimated labels and actual labels are ignored. A larger will yield a model with fewer support vectors, but will not generalize as well to future data. Generally, it has been suggested that epsilon should increase with noisier data, and decrease with the number of samples. See [5].
for -regression. Ignored during classification. When training the model, differences of less than between estimated labels and actual labels are ignored. A larger will yield a model with fewer support vectors, but will not generalize as well to future data. Generally, it has been suggested that epsilon should increase with noisier data, and decrease with the number of samples. See [5].
Default: NULL. Name of the input table that contains values of epsilon for different groups. Ignored when grouping_col is NULL. Define this input table if you want different epsilon values for different groups. The table consists of a column named epsilon which specifies the epsilon values, and one or more columns for grouping_col. Extra groups are ignored, and groups not present in this table will use the epsilon value specified in parameter epsilon.
Default: NULL. Name of the table to store the cross validation results including the values of parameters and their averaged error values. For now, simple metric like 0-1 loss is used for classification and mean square error is used for regression. The table is only created if the name is not NULL.
Default: 0. Number of folds (k). Must be at least 2 to activate cross validation. If a value of k > 2 is specified, each fold is then used as a validation set once, while the other k - 1 folds form the training set.
Default: 1 for classification, 'balanced' for one-class novelty detection, n/a for regression.
Set the weight for the positive and negative classes. If not given, all classes are set to have weight one. If class_weight = balanced, values of y are automatically adjusted as inversely proportional to class frequencies in the input data i.e. the weights are set as n_samples / (n_classes * bincount(y)).
Alternatively, class_weight can be a mapping, giving the weight for each class. Eg. For dependent variable values 'a' and 'b', the class_weight can be {a: 2, b: 3}. This would lead to each 'a' tuple's y value multiplied by 2 and each 'b' y value will be multiplied by 3.
For regression, the class weights are always one.
svm_predict(model_table,
new_data_table,
id_col_name,
output_table)
Arguments
TEXT. Model table produced by the training function.
TEXT. Name of the table containing the prediction data. This table is expected to contain the same features that were used during training. The table should also contain id_col_name used for identifying each row.
TEXT. The name of the id column in the input table.
| id | Gives the 'id' for each prediction, corresponding to each row from the new_data_table. |
|---|---|
| prediction | Provides the prediction for each row in new_data_table. For regression this would be the same as decision_function. For classification, this will be one of the dependent variable values. |
| decision_function | Provides the distance between each point and the separating hyperplane. |
DROP TABLE IF EXISTS houses;
CREATE TABLE houses (id INT, tax INT, bedroom INT, bath FLOAT, price INT,
size INT, lot INT);
COPY houses FROM STDIN WITH DELIMITER '|';
1 | 590 | 2 | 1 | 50000 | 770 | 22100
2 | 1050 | 3 | 2 | 85000 | 1410 | 12000
3 | 20 | 3 | 1 | 22500 | 1060 | 3500
4 | 870 | 2 | 2 | 90000 | 1300 | 17500
5 | 1320 | 3 | 2 | 133000 | 1500 | 30000
6 | 1350 | 2 | 1 | 90500 | 820 | 25700
7 | 2790 | 3 | 2.5 | 260000 | 2130 | 25000
8 | 680 | 2 | 1 | 142500 | 1170 | 22000
9 | 1840 | 3 | 2 | 160000 | 1500 | 19000
10 | 3680 | 4 | 2 | 240000 | 2790 | 20000
11 | 1660 | 3 | 1 | 87000 | 1030 | 17500
12 | 1620 | 3 | 2 | 118600 | 1250 | 20000
13 | 3100 | 3 | 2 | 140000 | 1760 | 38000
14 | 2070 | 2 | 3 | 148000 | 1550 | 14000
15 | 650 | 3 | 1.5 | 65000 | 1450 | 12000
\.
DROP TABLE IF EXISTS houses_svm, houses_svm_summary;
SELECT madlib.svm_classification('houses',
'houses_svm',
'price < 100000',
'ARRAY[1, tax, bath, size]'
);
-- Set extended display on for easier reading of output \x ON SELECT * FROM houses_svm;Result:
-[ RECORD 1 ]------+---------------------------------------------------------------
coef | {0.152192069515,-0.29631947495,0.0968619000065,0.362682248051}
loss | 601.279740124
norm_of_gradient | 1300.96615851627
num_iterations | 100
num_rows_processed | 15
num_rows_skipped | 0
dep_var_mapping | {f,t}
DROP TABLE IF EXISTS houses_svm_gaussian, houses_svm_gaussian_summary, houses_svm_gaussian_random;
SELECT madlib.svm_classification( 'houses',
'houses_svm_gaussian',
'price < 100000',
'ARRAY[1, tax, bath, size]',
'gaussian',
'n_components=10',
'',
'init_stepsize=1, max_iter=200'
);
-- Set extended display on for easier reading of output \x ON SELECT * FROM houses_svm_gaussian;Result:
-[ RECORD 1 ]------+--------------------------------------------------------------------------------------------------------------------------------------------------
coef | {0.183800813574,-0.78724997813,1.54121854068,1.24432527042,4.01230959334,1.07061097224,-4.92576349408,0.437699542875,0.3128600981,-1.63880635658}
loss | 0.998735180388
norm_of_gradient | 0.729823950583579
num_iterations | 196
num_rows_processed | 15
num_rows_skipped | 0
dep_var_mapping | {f,t}
DROP TABLE IF EXISTS houses_svm_regression, houses_svm_regression_summary;
SELECT madlib.svm_regression('houses',
'houses_svm_regression',
'price',
'ARRAY[1, tax, bath, size]'
);
For a non-linear regression model using a Gaussian kernel:
DROP TABLE IF EXISTS houses_svm_gaussian_regression, houses_svm_gaussian_regression_summary, houses_svm_gaussian_regression_random;
SELECT madlib.svm_regression( 'houses',
'houses_svm_gaussian_regression',
'price',
'ARRAY[1, tax, bath, size]',
'gaussian',
'n_components=10',
'',
'init_stepsize=1, max_iter=200'
);
DROP TABLE IF EXISTS houses_one_class_gaussian, houses_one_class_gaussian_summary, houses_one_class_gaussian_random;
select madlib.svm_one_class('houses',
'houses_one_class_gaussian',
'ARRAY[1,tax,bedroom,bath,size,lot,price]',
'gaussian',
'gamma=0.5,n_components=55, random_state=3',
NULL,
'max_iter=100, init_stepsize=10,lambda=10, tolerance=0'
);
-- Set extended display on for easier reading of output \x ON SELECT * FROM houses_one_class_gaussian;Result:
-[ RECORD 1 ]------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------
coef | {redacted for brevity}
loss | 15.1053343738
norm_of_gradient | 13.9133653663837
num_iterations | 100
num_rows_processed | 16
num_rows_skipped | -1
dep_var_mapping | {-1,1}
DROP TABLE IF EXISTS houses_pred;
SELECT madlib.svm_predict('houses_svm', 'houses', 'id', 'houses_pred');
SELECT *, price < 100000 AS target FROM houses JOIN houses_pred USING (id) ORDER BY id;
Result: id | tax | bedroom | bath | price | size | lot | prediction | decision_function | target ----+------+---------+------+--------+------+-------+------------+--------------------+-------- 1 | 590 | 2 | 1 | 50000 | 770 | 22100 | t | 104.685894748292 | t 2 | 1050 | 3 | 2 | 85000 | 1410 | 12000 | t | 200.592436923938 | t 3 | 20 | 3 | 1 | 22500 | 1060 | 3500 | t | 378.765847404582 | t 4 | 870 | 2 | 2 | 90000 | 1300 | 17500 | t | 214.034895129328 | t 5 | 1320 | 3 | 2 | 133000 | 1500 | 30000 | t | 153.227581012028 | f 6 | 1350 | 2 | 1 | 90500 | 820 | 25700 | f | -102.382793811158 | t 7 | 2790 | 3 | 2.5 | 260000 | 2130 | 25000 | f | -53.8237999423388 | f 8 | 680 | 2 | 1 | 142500 | 1170 | 22000 | t | 223.090041223192 | f 9 | 1840 | 3 | 2 | 160000 | 1500 | 19000 | f | -0.858545961972027 | f 10 | 3680 | 4 | 2 | 240000 | 2790 | 20000 | f | -78.226279884182 | f 11 | 1660 | 3 | 1 | 87000 | 1030 | 17500 | f | -118.078558954948 | t 12 | 1620 | 3 | 2 | 118600 | 1250 | 20000 | f | -26.3388234857219 | f 13 | 3100 | 3 | 2 | 140000 | 1760 | 38000 | f | -279.923699905712 | f 14 | 2070 | 2 | 3 | 148000 | 1550 | 14000 | f | -50.7810508979155 | f 15 | 650 | 3 | 1.5 | 65000 | 1450 | 12000 | t | 333.579085875975 | tPrediction using the Gaussian model:
DROP TABLE IF EXISTS houses_pred_gaussian;
SELECT madlib.svm_predict('houses_svm_gaussian', 'houses', 'id', 'houses_pred_gaussian');
SELECT *, price < 100000 AS target FROM houses JOIN houses_pred_gaussian USING (id) ORDER BY id;
This produces a more accurate result than the linear case for this small data set: id | tax | bedroom | bath | price | size | lot | prediction | decision_function | target ----+------+---------+------+--------+------+-------+------------+-------------------+-------- 1 | 590 | 2 | 1 | 50000 | 770 | 22100 | t | 1.00338548176312 | t 2 | 1050 | 3 | 2 | 85000 | 1410 | 12000 | t | 1.00000000098154 | t 3 | 20 | 3 | 1 | 22500 | 1060 | 3500 | t | 0.246566699635389 | t 4 | 870 | 2 | 2 | 90000 | 1300 | 17500 | t | 1.0000000003367 | t 5 | 1320 | 3 | 2 | 133000 | 1500 | 30000 | f | -1.98940593324397 | f 6 | 1350 | 2 | 1 | 90500 | 820 | 25700 | t | 3.74336995109761 | t 7 | 2790 | 3 | 2.5 | 260000 | 2130 | 25000 | f | -1.01574407296086 | f 8 | 680 | 2 | 1 | 142500 | 1170 | 22000 | f | -1.0000000002071 | f 9 | 1840 | 3 | 2 | 160000 | 1500 | 19000 | f | -3.88267069310101 | f 10 | 3680 | 4 | 2 | 240000 | 2790 | 20000 | f | -3.44507576539002 | f 11 | 1660 | 3 | 1 | 87000 | 1030 | 17500 | t | 2.3409866081761 | t 12 | 1620 | 3 | 2 | 118600 | 1250 | 20000 | f | -3.51563221173085 | f 13 | 3100 | 3 | 2 | 140000 | 1760 | 38000 | f | -1.00000000011163 | f 14 | 2070 | 2 | 3 | 148000 | 1550 | 14000 | f | -1.87710363254055 | f 15 | 650 | 3 | 1.5 | 65000 | 1450 | 12000 | t | 1.34334834982263 | t
DROP TABLE IF EXISTS houses_regr;
SELECT madlib.svm_predict('houses_svm_regression', 'houses', 'id', 'houses_regr');
SELECT * FROM houses JOIN houses_regr USING (id) ORDER BY id;
Result for the linear regression model: id | tax | bedroom | bath | price | size | lot | prediction | decision_function ----+------+---------+------+--------+------+-------+------------------+------------------- 1 | 590 | 2 | 1 | 50000 | 770 | 22100 | 55288.6992755623 | 55288.6992755623 2 | 1050 | 3 | 2 | 85000 | 1410 | 12000 | 99978.8137019119 | 99978.8137019119 3 | 20 | 3 | 1 | 22500 | 1060 | 3500 | 43157.5130381023 | 43157.5130381023 4 | 870 | 2 | 2 | 90000 | 1300 | 17500 | 88098.9557296729 | 88098.9557296729 5 | 1320 | 3 | 2 | 133000 | 1500 | 30000 | 114803.884262468 | 114803.884262468 6 | 1350 | 2 | 1 | 90500 | 820 | 25700 | 88899.5186193813 | 88899.5186193813 7 | 2790 | 3 | 2.5 | 260000 | 2130 | 25000 | 201108.397013076 | 201108.397013076 8 | 680 | 2 | 1 | 142500 | 1170 | 22000 | 75004.3236915733 | 75004.3236915733 9 | 1840 | 3 | 2 | 160000 | 1500 | 19000 | 136434.749667136 | 136434.749667136 10 | 3680 | 4 | 2 | 240000 | 2790 | 20000 | 264483.856987395 | 264483.856987395 11 | 1660 | 3 | 1 | 87000 | 1030 | 17500 | 110180.048139857 | 110180.048139857 12 | 1620 | 3 | 2 | 118600 | 1250 | 20000 | 117300.841695563 | 117300.841695563 13 | 3100 | 3 | 2 | 140000 | 1760 | 38000 | 199229.683967752 | 199229.683967752 14 | 2070 | 2 | 3 | 148000 | 1550 | 14000 | 147998.930271016 | 147998.930271016 15 | 650 | 3 | 1.5 | 65000 | 1450 | 12000 | 84936.7661235861 | 84936.7661235861For the non-linear Gaussian regression model (output not shown):
DROP TABLE IF EXISTS houses_gaussian_regr;
SELECT madlib.svm_predict('houses_svm_gaussian_regression', 'houses', 'id', 'houses_gaussian_regr');
SELECT * FROM houses JOIN houses_gaussian_regr USING (id) ORDER BY id;
DROP TABLE IF EXISTS houses_one_class_test;
CREATE TABLE houses_one_class_test (id INT, tax INT, bedroom INT, bath FLOAT, price INT,
size INT, lot INT);
COPY houses_one_class_test FROM STDIN WITH DELIMITER '|';
1 | 3100 | 3 | 2 | 140000 | 1760 | 38000
2 | 2070 | 2 | 3 | 148000 | 1550 | 14000
3 | 650 | 3 | 1.5 | 65000 | 1450 | 12000
4 | 650 | 3 | 1.5 | 650000 | 1450 | 12000
\.
Now run prediction on the Gaussian one-class novelty detection model:
DROP TABLE IF EXISTS houses_once_class_pred;
SELECT madlib.svm_predict('houses_one_class_gaussian', 'houses_one_class_test', 'id', 'houses_one_class_pred');
SELECT * FROM houses_one_class_test JOIN houses_one_class_pred USING (id) ORDER BY id;
Result showing the last row predicted to be novel: id | tax | bedroom | bath | price | size | lot | prediction | decision_function ----+------+---------+------+--------+------+-------+------------+--------------------- 1 | 3100 | 3 | 2 | 140000 | 1760 | 38000 | 1 | 0.111497008121437 2 | 2070 | 2 | 3 | 148000 | 1550 | 14000 | 1 | 0.0996021345169148 3 | 650 | 3 | 1.5 | 65000 | 1450 | 12000 | 1 | 0.0435064008756942 4 | 650 | 3 | 1.5 | 650000 | 1450 | 12000 | -1 | -0.0168967845338403
DROP TABLE IF EXISTS houses_svm_gaussian, houses_svm_gaussian_summary, houses_svm_gaussian_random;
SELECT madlib.svm_classification( 'houses',
'houses_svm_gaussian',
'price < 150000',
'ARRAY[1, tax, bath, size]',
'gaussian',
'n_components=10',
'',
'init_stepsize=1, max_iter=200, class_weight=balanced'
);
SELECT * FROM houses_svm_gaussian;
-[ RECORD 1 ]------+----------------------------------------------------------------------------------------------------------------------------------------------------
coef | {-0.621843913637,2.4166374426,-1.54726833725,-1.74512599505,1.16231799548,-0.54019307285,-4.14373293694,-0.623069170717,3.59669949057,-1.005501237}
loss | 1.87657250199
norm_of_gradient | 1.41148000266816
num_iterations | 174
num_rows_processed | 15
num_rows_skipped | 0
dep_var_mapping | {f,t}
Note that the results you get for all examples may vary with the platform you are using.To solve linear SVM, the following objective function is minimized:
![\[ \underset{w,b}{\text{Minimize }} \lambda||w||^2 + \frac{1}{n}\sum_{i=1}^n \ell(y_i,f_{w,b}(x_i)) \]](form_529.png)
where  are labeled training data and
are labeled training data and 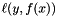 is a loss function. When performing classification,
is a loss function. When performing classification, 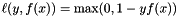 is the hinge loss. For regression, the loss function
is the hinge loss. For regression, the loss function 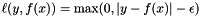 is used.
is used.
If 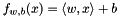 is linear, then the objective function is convex and incremental gradient descent (IGD, or SGD) can be applied to find a global minimum. See Feng, et al. [1] for more details.
is linear, then the objective function is convex and incremental gradient descent (IGD, or SGD) can be applied to find a global minimum. See Feng, et al. [1] for more details.
To learn with Gaussian or polynomial kernels, the training data is first mapped via a random feature map in such a way that the usual inner product in the feature space approximates the kernel function in the input space. The linear SVM training function is then run on the resulting data. See the papers [2,3] for more information on random feature maps.
Also, see the book [4] by Scholkopf and Smola for more details on SVMs in general.
[1] Xixuan Feng, Arun Kumar, Ben Recht, and Christopher Re: Towards a Unified Architecture for in-RDBMS analytics, in SIGMOD Conference, 2012 http://www.eecs.berkeley.edu/~brecht/papers/12.FengEtAl.SIGMOD.pdf
[2] Purushottam Kar and Harish Karnick: Random Feature Maps for Dot Product Kernels, Proceedings of the 15th International Conference on Artificial Intelligence and Statistics, 2012, http://machinelearning.wustl.edu/mlpapers/paper_files/AISTATS2012_KarK12.pdf
[3] Ali Rahmini and Ben Recht: Random Features for Large-Scale Kernel Machines, Neural Information Processing Systems 2007, http://www.eecs.berkeley.edu/~brecht/papers/07.rah.rec.nips.pdf
[4] Bernhard Scholkopf and Alexander Smola: Learning with Kernels, The MIT Press, Cambridge, MA, 2002.
[5] Vladimir Cherkassky and Yunqian Ma: Practical Selection of SVM Parameters and Noise Estimation for SVM Regression, Neural Networks, 2004 http://www.ece.umn.edu/users/cherkass/N2002-SI-SVM-13-whole.pdf
File svm.sql_in documenting the training function
 1.8.13
1.8.13